采坑系列是记录日常学习/工作中所遇到的问题,可能是一个Bug、一次性能优化、一次思考等,目的是记录自己所处理过的问题,以及解决问题这一过程中所做的思考或总结,避免后续再犯相似的错误。
问题描述
近期线上的排序服务在某个时间点内出现了大量特征获取超时告警,大概是集中在中午12点左右和下午4点左右,告警持续一会后就自动恢复了,下面是某一天的告警情况:
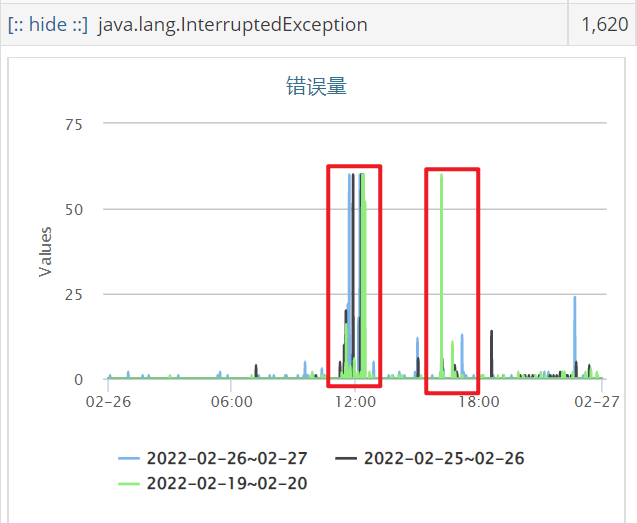
服务获取特征是以本地存储(基于Rocksdb)的方式获取的,且内存缓存配置得足够多,数据基本都是从内存中读取,耗时一般在几毫秒左右;看代码在获取特征的地方限制了300ms超时,正常情况下应该不会超过这个时间的,除非是有什么操作导致了获取数据得去读磁盘。
探究原因
初探
基于以上的想法,首先排查看是否在产生超时的那个时间内,磁盘的读会比正常情况大,下面是服务的某个实例机的I/O监控:
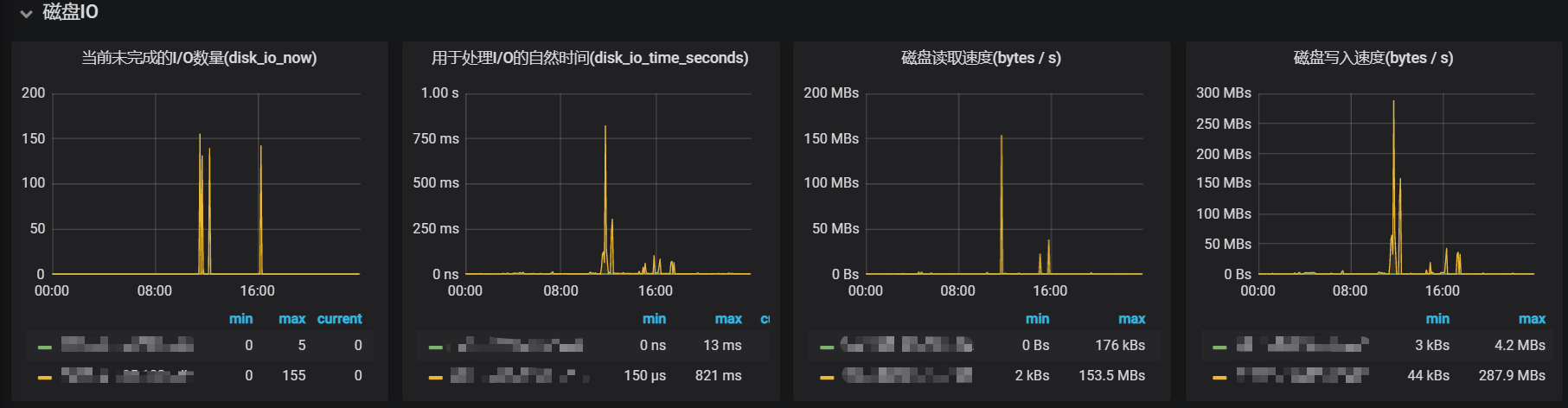
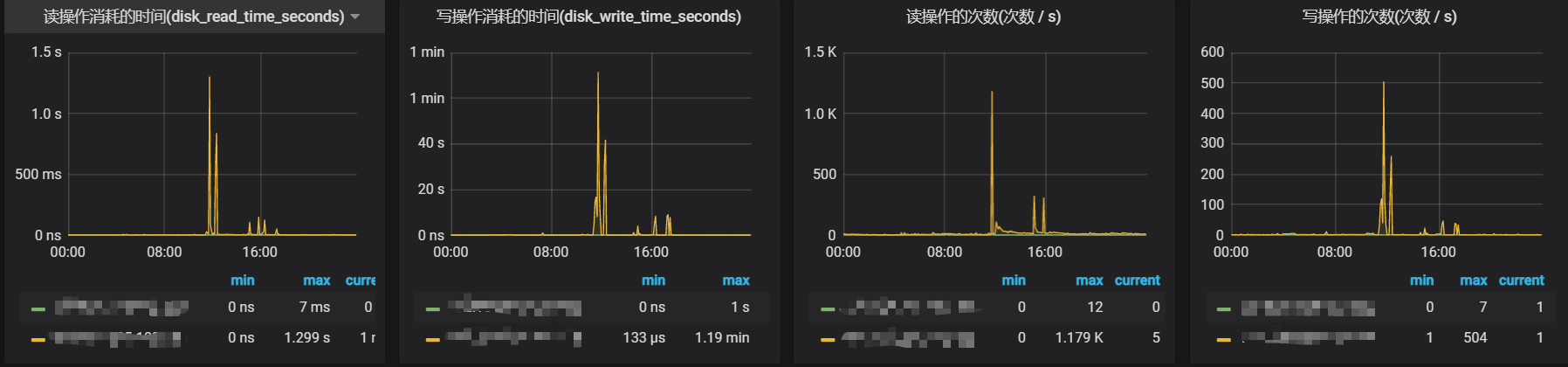
基于上面两张监控图可以看到,确实在异常的时间点,磁盘的读会比其他时间段大很多,最大耗时到了 1s 以上,这种情况已经远超过设置的 300ms 超时时间了。此外,在这里也注意到了磁盘的写入速度也异常的大,峰值达到了287.9MB/s。观察到这里,猜测可能是磁盘的写过大导致读响应慢了(个人直觉-。-,具体未去验证),下面就是找出具体是什么原因导致那段时间内磁盘写入速度辣么大。
再探
服务内部获取特征使用到的本地存储框架,是基于Rocksdb存储开发的,下面是该框架与服务的简单交互流程:
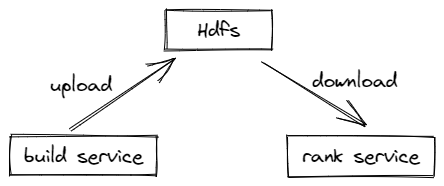
由一个索引服务去同步特征数据写成Rocksdb表,再将写好的Rocksdb文件打包压缩(tar文件)上传到Hdfs上
排序服务从Hdfs上下载索引服务上传的tar文件到本地,再进行解包解压,然后恢复成Rocksdb表提供查询
根据这个流程,再结合服务内部的一些日志,查到了在异常发生的时间段内会有表索引下载操作,所以认为可能是下载Hdfs文件到本地这一操作导致磁盘写入过快,因此在下载那里做了一个限速尝试,但上线后依然写入没有下降。后来再仔细对比了下载日志与磁盘写入监控,发现磁盘写入飙升的时间点刚好是tar文件刚下载完成后,所以猜测可能是tar文件的解压所导致的,接着查看了代码内tar文件的解压方式,发现内部是采用Linux的tar命令去做解压的,再从网上查到tar命令确实会有解压速度的问题。
解决方法
解决tar命令解压写入速度过快的方法,从网上找到了一种方法说可以结合pv命令使用,但因为考虑安装服务的机器可能没有pv命令,所以没有采用这种方法。因考虑到用命令的方式无法控制写入速度,所以后面决定改用Java的方式去解压,这里采用了Apache的commons-compress里面的TarArchiveInputStream去做解压,具体实现如下:
| |
更换了解压方式后,磁盘写入速度峰值降到了90MB/s左右,磁盘读耗时峰值也降到了300ms,下面是更换后的I/O监控:
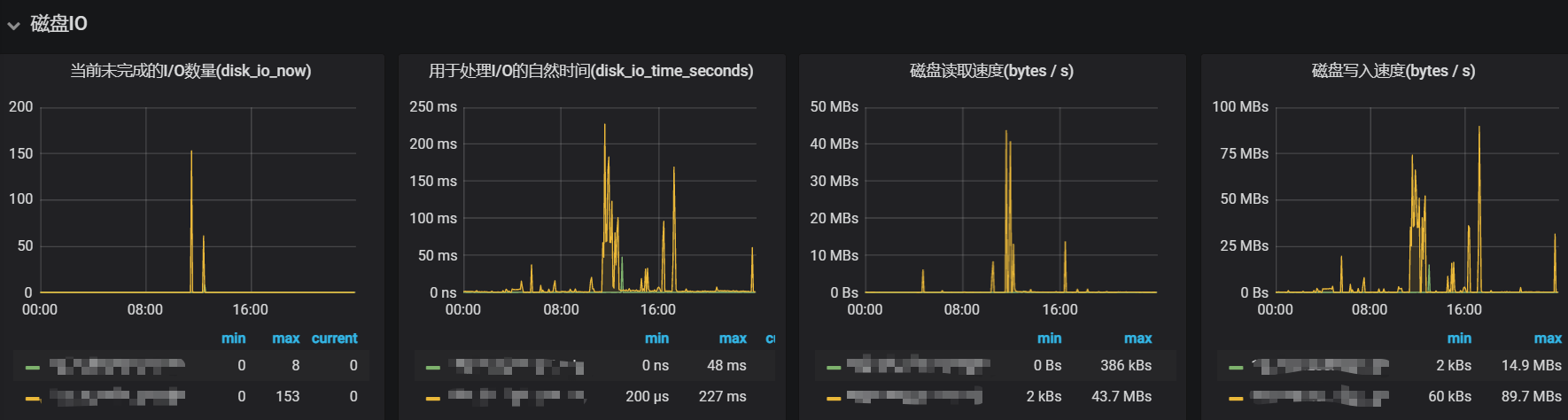
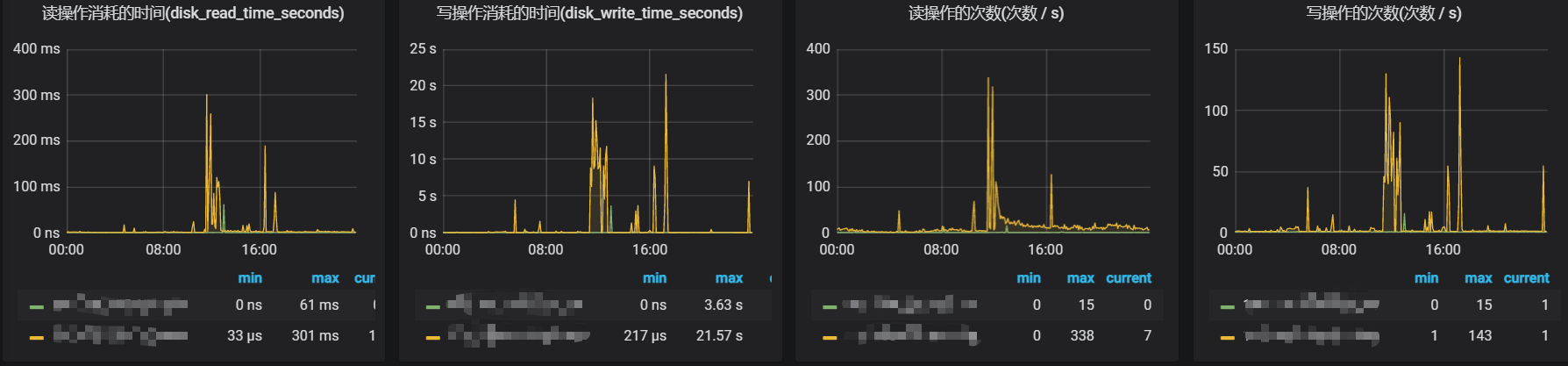
异常超时的量也从原来的1600多个,降到了200多个,下面是更换后的异常超时监控:
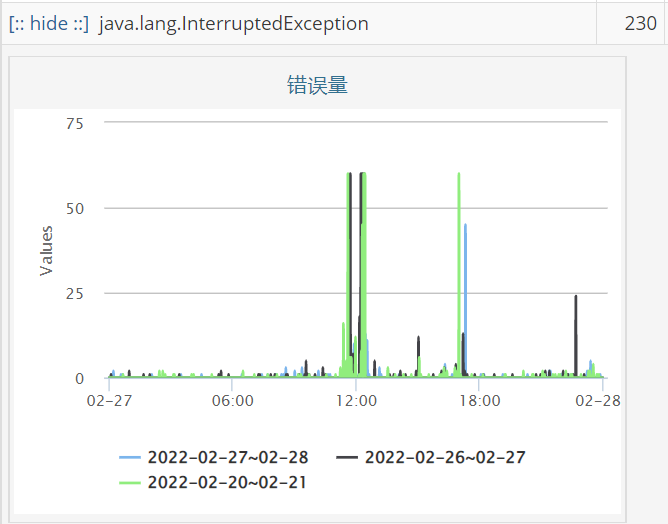
后面发现存储框架那边的流程其实可以简化,让排序服务直接读取Hdfs上的tar文件并解压到本地,可以省去从Hdfs上下载文件到本地的过程,不仅减少了索引下载到加载的时间,而且也减少了磁盘的写入,修改后的磁盘写入速度下降到了50MB/s以下,磁盘读取耗时峰值降到了170ms左右,异常超时发生的数量也减了不少。
总结
本次所遇到的问题算是比较不常见的,因为日常做业务开发涉及到磁盘I/O的可能会比较少,因此也很少关注这方面的问题;刚好是服务用到了本地存储这个对磁盘读写比较敏感的东西,磁盘有一点比较大的波动就可能对服务性能产生影响,因此需要特别留意磁盘的写入速度。这次排查能够比较顺利很大的功劳在于监控系统,在业务监控系统能够看到异常发生的问题点以及时间点,在基础监控系统能够看到机器磁盘I/O的变化情况,再结合部分业务日志,定位问题显然高效了许多,所以有一套比较完善的监控体系真挺重要的。