对线上特征统一进行管理,规范特征生产、存储、查询流程,降低特征的使用成本和维护成本
背景
在推荐业务场景日益增多的情况下,推荐所需要的特征也在不断增多,现有的特征使用情况逐渐暴露了以下使用问题:
写入比较分散,每个人都生产自己需要的特征,写入格式杂乱,不能达到很好的特征复用
特征存储在HBase上,HBase集群运维成本大,偶尔发生不稳定的情况(因写入大影响到查询等),导致大量特征查询超时
特征使用情况不明确,不能很清楚各个服务对特征的依赖
为解决以上问题,工程同事推动了特征平台的建设,期望满足以下核心诉求:
化零为整:提供web界面,统一管理特征的读写
稳定可靠:降低特征服务读取延时
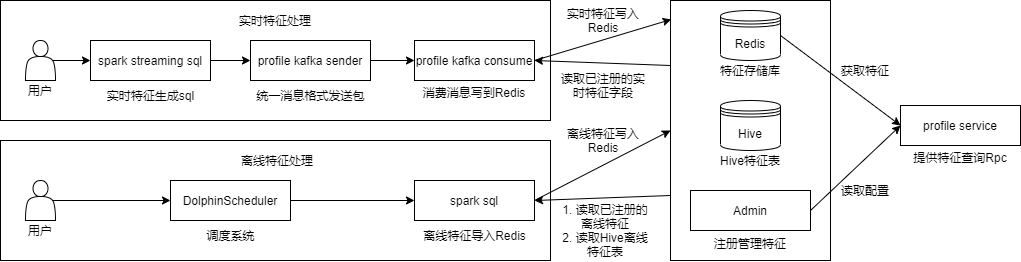
平台架构
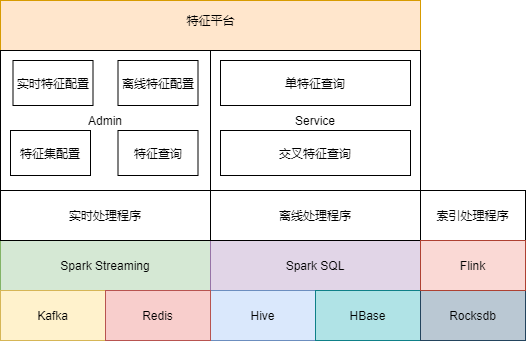
架构图由下向上分别是:
存储层
Kafka:用于接收实时特征
Redis、HBase:用于存放特征(离线+实时),提供在线查询,其中离线特征在Redis中采取压缩手段以节省内存
Hive:用于存放离线特征
Rocksdb:用于存放物品特征(离线+实时),提供在线查询,替换Redis中存储的物品特征
计算层
Spark Streaming、Flink:用于生产实时特征
Spark SQL:用于同步Hive离线特征到在线的存储
业务处理层
实时处理程序:接收Kafka实时特征,写入Redis
离线处理程序:同步Hive离线特征,写入Redis
索引处理程序:接收Kafka实时特征 + 同步Hive离线特征,写入Rocksdb
接入层
Admin:特征管理界面,提供离线/实时特征注册、特征集配置、特征查询功能
Service:提供特征查询Rpc接口
核心功能
特征生产
离线特征
目前在离线特征生产方面工程同学暂时还未有过多的介入,这方面的特征大都是算法同学通过Hive SQL计算提取出来,工程同学暂仅限于提供一些UDF函数支持。算法同学在这一过程最终会生产出多张Hive特征表,供后续流程使用。
实时特征
对于实时特征方面,工程同学尝试利用Spark Streaming结合Spark SQL定义一个规范处理流程(统一输入+SQL+统一输出),让算法同学可以在界面上编写SQL来生产实时特征,同时工程同学可以在流程内加入一些监控、告警等辅助功能,下面是Spark Streaming程序定义的界面:
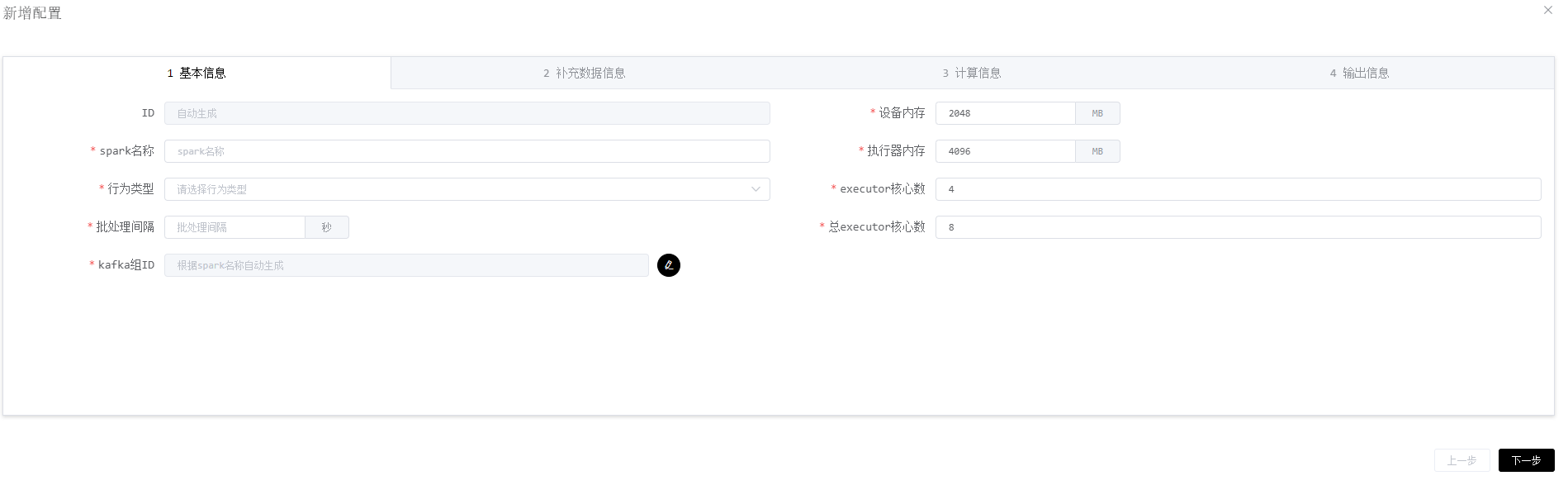
基本信息:填写Spark Streaming程序的一些基础信息
补充数据信息:可以从其他数据源(如HBase)关联补充一些数据
计算信息:编写SQL
输出信息:指定输出结果存储到哪里
功能上线后陆续接入了几个生产程序,整体效果还是可以的,相比之前每个算法同学都自己编写和维护自己的Spark Streaming程序,使用这种方式明显减少了算法同学的开发以及维护成本。
特征存储
基于Redis存储
特征类型:离线+实时
特征版本:单版本,用新数据直接覆盖旧数据,实现简单,对物理存储占用较少,但在数据异常时无法快速回滚
特征序列化
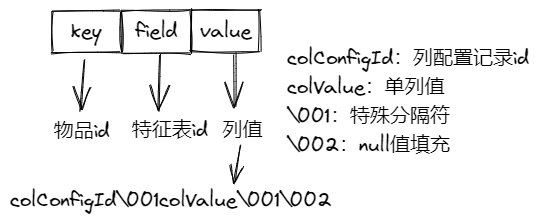
单表离线特征:hash结构,key为物品id,field为离线特征表id,value为所有特征列拼接的值(colConfigId\001colValue\001colValue,其中colConfigId为列配置记录id,\001为特殊分隔符,colValue为列值,colValue为null时用\002填充,采用Snappy压缩value以节省空间)
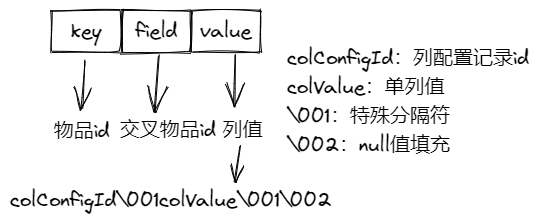
交叉表离线特征:hash结构,key为物品id,field为交叉物品id,value为所有特征列拼接的值(colConfigId\001colValue\001colValue,其中colConfigId为列配置记录id,\001为特殊分隔符,colValue为列值,colValue为null时用\002填充,采用Snappy压缩value以节省空间)
单表实时特征:hash结构,key为物品id_rt(_rt为后缀字符串,与离线特征区分),field为实时字段名,value为实时字段值
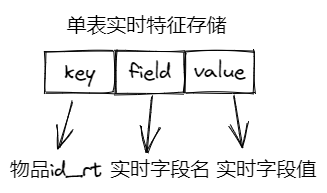
交叉表实时特征:hash结构,key为物品id_rt(_rt为后缀字符串,与离线特征区分),field为交叉物品id,value为实时字段key-value json串
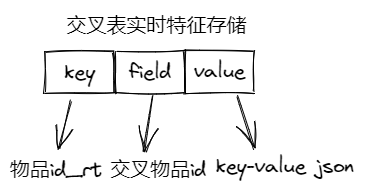
PS:离线特征过期时间为7天、实时特征过期时间为3天,具体根据实际业务场景设置
实现方式
离线:利用
SparkSQL读取Hive表数据通过Redis Pipline录入到Redis实时:利用
Spark Streaming生成实时特征发往Kafka,消费Kafka数据录入到Redis
优缺点
优点
实现简单
性能良好
缺点
用特殊值拼接各列值存在风险
不支持异常快速回滚
量大时更新较慢(为防止影响线上读控制了写入速率)
内存占用较多
基于Rocksdb存储
特征类型:离线+实时
特征版本:多版本,每一份数据对应特定版本,虽然物理存储占用较多,但在数据异常时可通过版本切换的方式快速回滚
PS:离线按天生成版本,全实时/离线+全实时按每6小时生成一个版本,具体根据实际业务场景调整
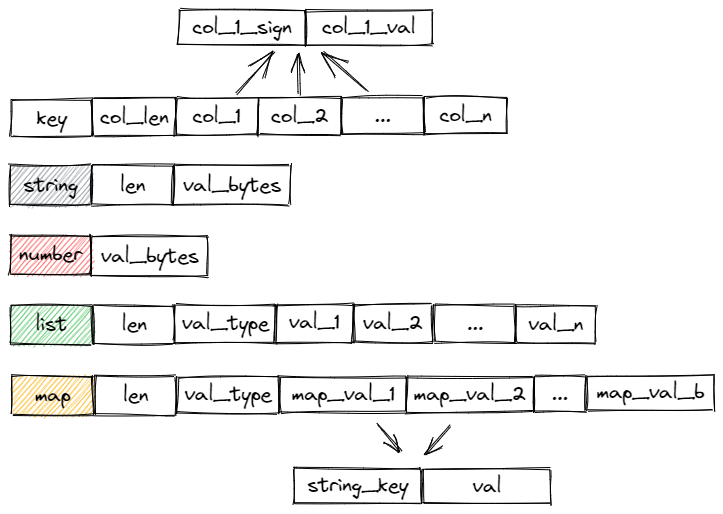
特征序列化
KV存储,Value使用自定义的序列化方式以二进制的方式紧凑存储,Value的存储格式为:col_len + col_1_sign + col_1_val + col_2_sign + col_2_val + … + col_n_sign + col_n_val(根据Schema定义的字段拼接字段值,col_len为定义的字段数,col_i_sign为字段是否为空标识,col_i_val为字段值)
支持多种数据类型的序列化
string:len + val_bytes
list:len + val_1_type + val_1 + val_2 + … + val_n
number:val_bytes
map:len + map_val_type + map_val_1 + map_val_2 + … + map_val_n
- map_val:str_key + val
实现方式
离线:由
BuildService读取Hive Metadata并解析Hdfs File数据生成Key-Value录入到Rocksdb Table,录入完成后将Rocksdb Table在本地对应的文件打包压缩上传到Hdfs上,最终由OnlineService下载到本地并在内存中构建Rocksdb Table提供在线服务实时:由
BuildService消费Kafka数据录入到Rocksdb Table,消费到一定时间或数据时会生成一个版本,接着将Rocksdb Table在本地对应的文件打包压缩上传到Hdfs上,由OnlineService下载到本地并在内存中构建Rocksdb Table提供在线服务,同时OnlineService也会基于下载版本所消费到的offset继续消费数据往表中插入/更新数据
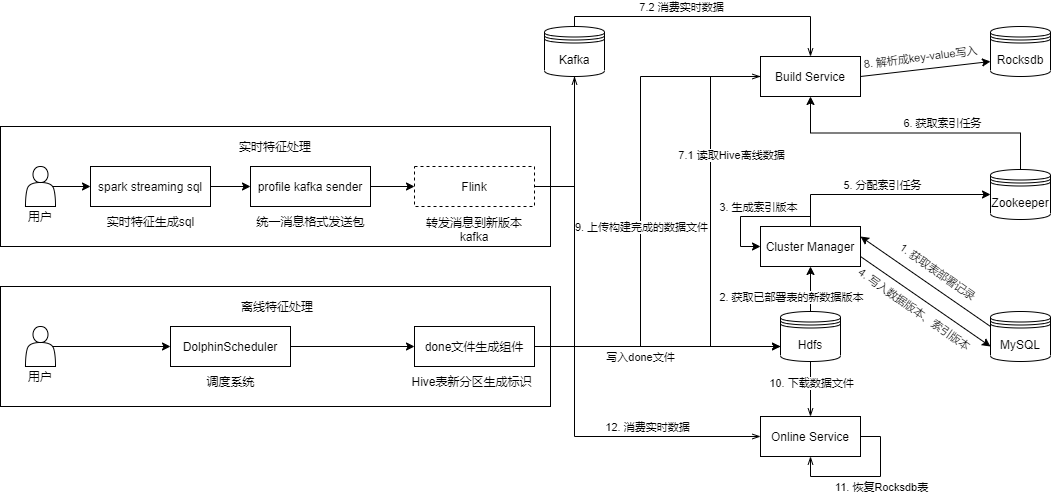
优缺点
优点
内存占用较少
性能良好
多版本支持异常回滚
缺点
- 实现较复杂,需要进行调优
特征查询
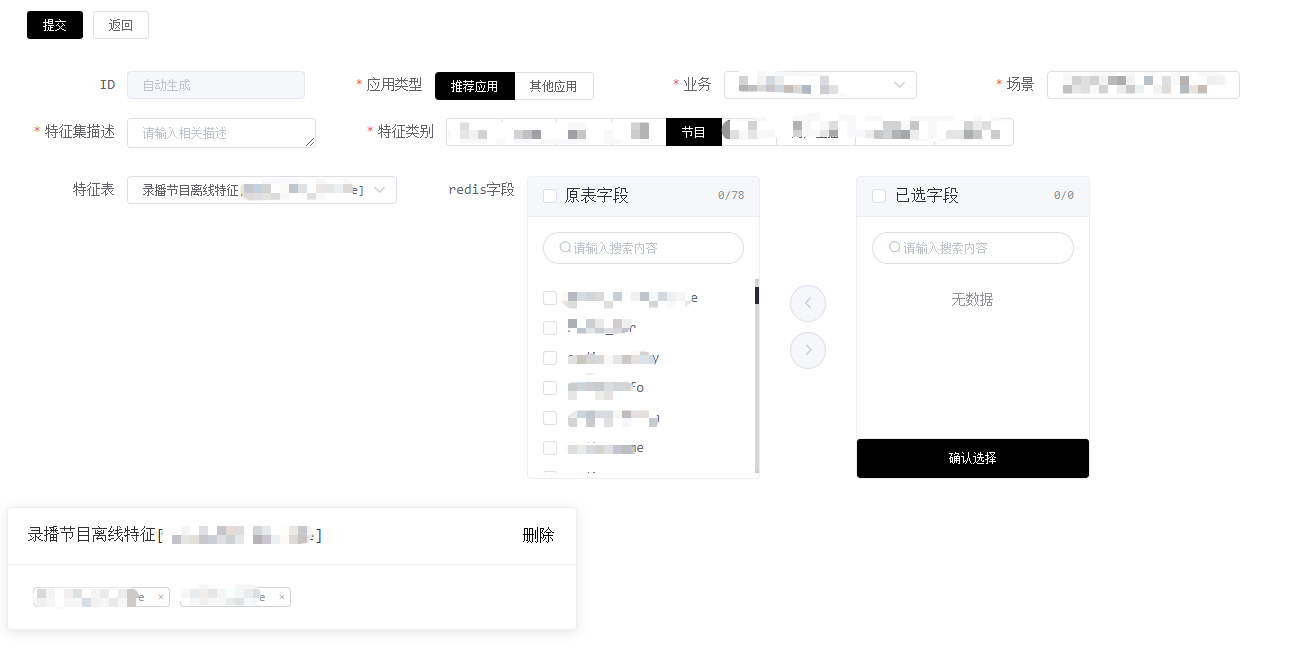
特征查询需要先通过界面配置申请特征集(多个特征)查询key,一个key可以关联多个特征,使用方调用特征查询服务时只需传入这个key,服务内部会根据key去获取关联的特征,拿到结果后返回给使用方,下面是特征集的定义和展示界面:
展望未来
目前整个特征平台还不是很完善的,比如说离线特征生产这一块,完全还是由算法同学自己去生产,未实现任何工程保障,可能出现类似特征重复生产、特征异常未及时发现等问题。另外,在特征迁移到本地存储后,索引构建时间,特征查询毛刺现象等这些都是需要进行优化的。总的来说,特征平台未来可以在以下方面持续改进:
特征生产流程工程化
减少特征存储索引构建时间
提升特征查询服务的性能
特征监控