基于 Solrcloud 研发的大规模分布式搜索引擎平台,提供简单、高效、稳定、低成本和可扩展的搜索解决方案(核心:将不同数据源(Hive、MySQL、Kafka、文件等)的数据导入到Solr集群,对外提供检索服务)
背景
随着公司业务增长,需要对外提供站内搜索等搜索功能,早期维护人员采用了Solr作为检索引擎,搭建了Solrcloud集群,满足了当时的使用场景。但随着搜索的业务逐渐增多,在集群使用上存在的诸多问题逐渐暴露出来,比如每个业务接入都要手写程序同步数据(效率问题)、Collection数据来源分散难管理(管理问题)、查看数据需要到Solr自身的管理界面上查询(安全问题)等。为规范集群使用,解决以上众多问题,推动了搜索平台的建设,期望实现以下核心功能诉求:
提供异构数据源数据自动同步到Solr,无需编写任何代码
对外提供数据检索服务,屏蔽Solr自身检索的复杂性
平台架构
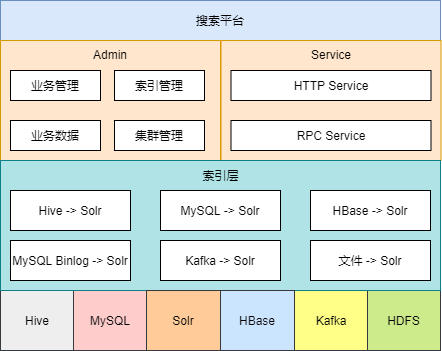
架构图由下向上分别是:
存储层
存储层包含Hive、MySQL、HBase、Kafka、HDFS等外部数据源,以及平台内部的Solr集群
平台目前暂不支持同步HBase数据源的数据,目前HBase主要用于连接(join)获取额外字段
索引层
索引层由多个子模块组成,分别处理来自不同数据源的数据,最终导入到Solr集群中
Hive → Solr:该模块基于开源的Hive-Solr组件进行数据同步
MySQL → Solr:该模块基于Sqoop将MySQL数据导入到Hive临时表,再利用Hive → Solr模块导入数据,增量部分利用MySQL Binlog → Solr模块处理
MySQL Binlog → Solr:该模块通过客户端消费统一的Canal Kafka Topic,使用Solr API写入数据
Kafka → Solr:该模块通过客户端消费指定的Kafka Topic,使用Solr API写入数据
文件 → Solr:该模块通过读取上传文件的数据,使用Solr API写入数据
接入层
接入层包含提供Web界面的Admin模块以及提供API接口的Service模块
Admin:提供业务接入、数据查询/导出、索引触发/查询、集群节点注册/监控等功能
Service:提供HTTP接口和RPC接口,包含查询、以及部分更新功能
核心功能
业务管理
业务是对外部数据源接入平台时的一个统称,每个业务都会对应一个外部数据源、一个Solr Collection以及其他的一些配置信息(如同步信息等),用户使用平台需要先走业务接入申请,然后由管理员审核(主要是针对用户的场景审核配置是否合理)激活,激活后用户可手动进行同步或等待定时任务生效进行同步。
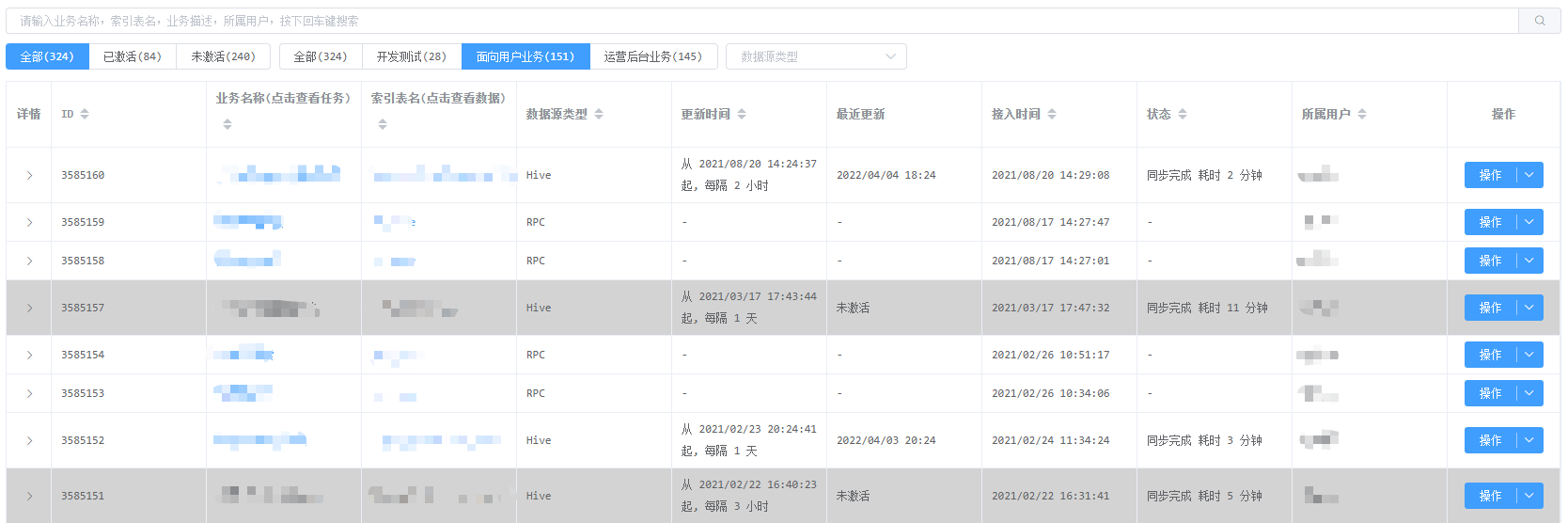
业务接入需要填写的信息包含三个部分:接入信息、数据来源、同步信息
业务接入-接入信息:
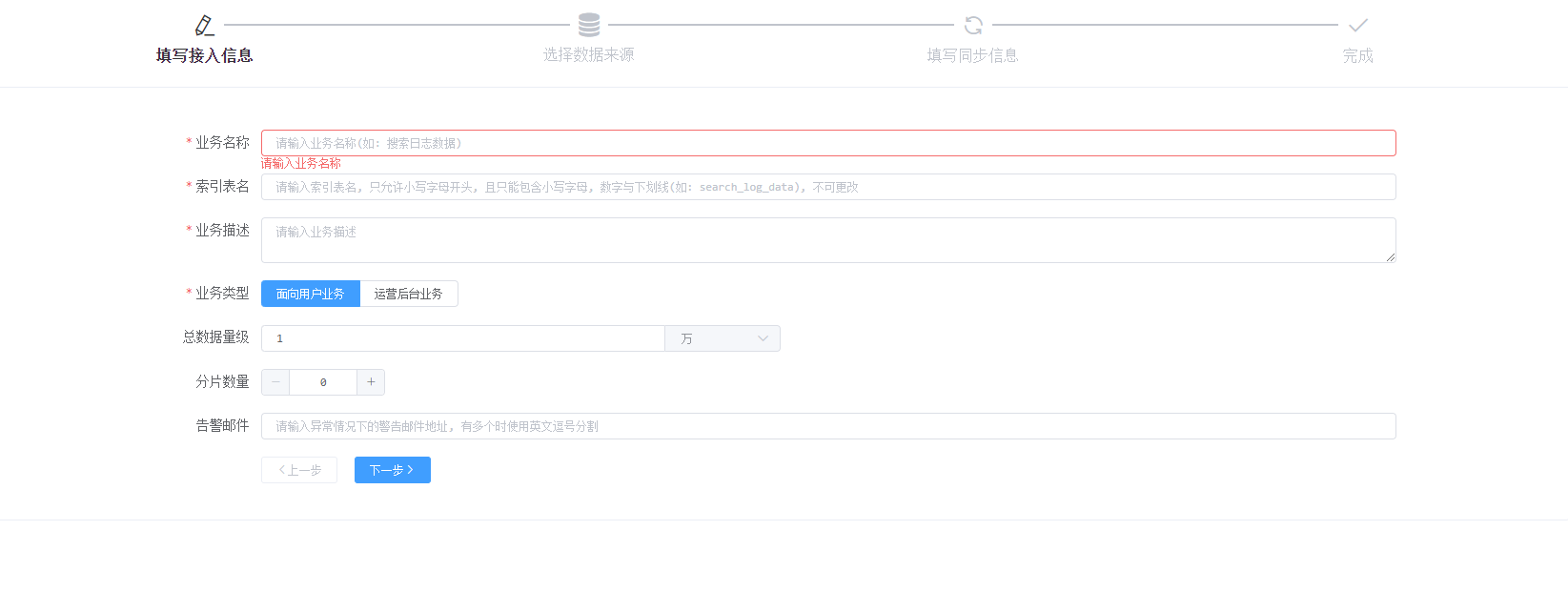
业务名称:对业务的一个简要描述
索引表名:Solr Collection名
业务描述:对业务的一个详细描述
业务类型:区分不同使用场景的业务,后续会针对不同类型的业务对Collection分配不同数量的分片
总数据量级:对数据量级的一个大致评估,后续会针对不同量级的业务对Collection分配不同数量的分片
分片数量:强制指定Collection的分片数量,未指定时会根据业务类型和数据量级进行决定
告警邮件:索引失败时接收通知的邮件,这里设计得有点不好,直填邮件的方式,容易因人员离职后邮件失效影响通知
业务接入-数据来源:
Hive接入是目前平台使用最多的接入方式,平台会从Hive对应的元数据库中读取Hive库、表、字段供用户选取
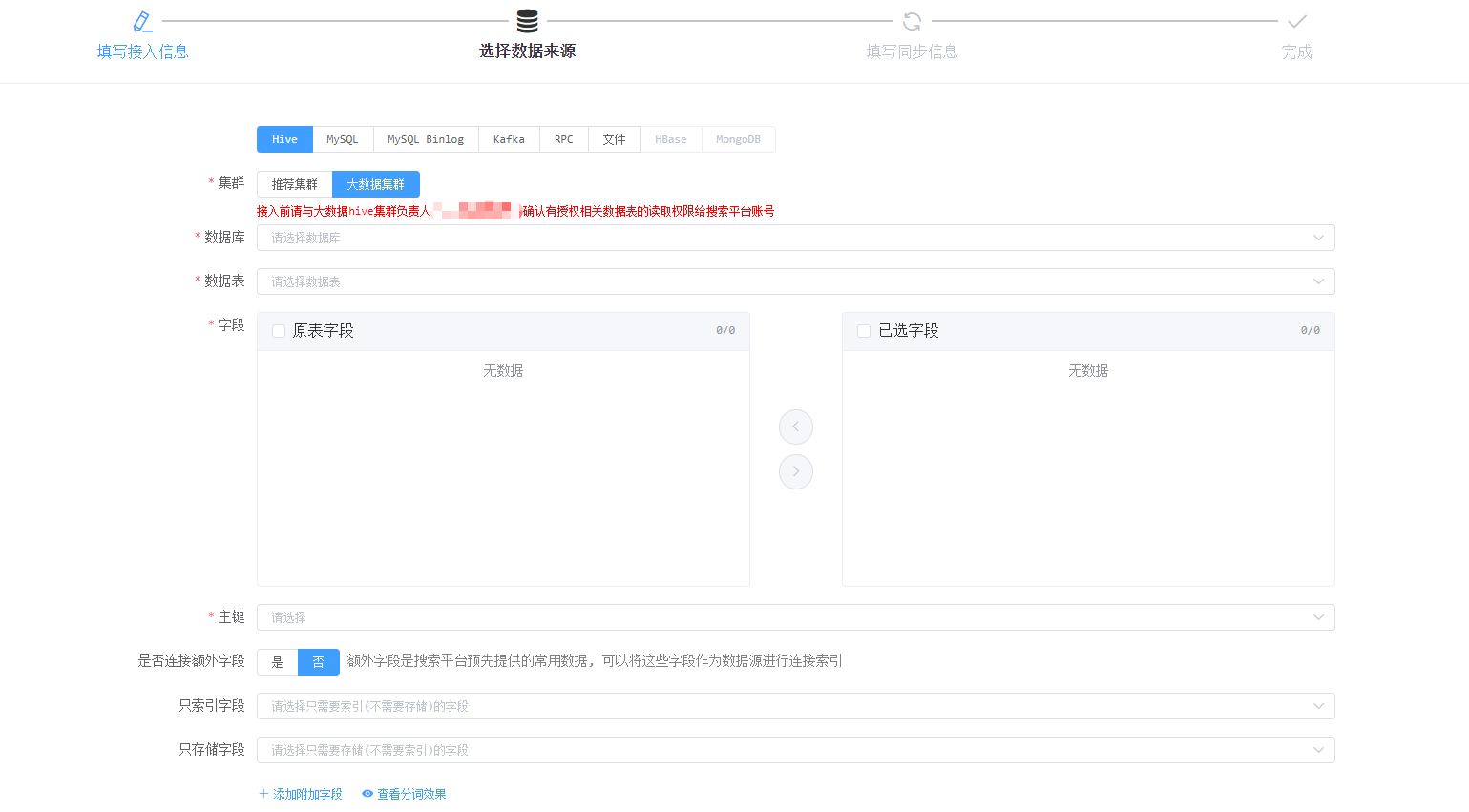
集群:因集群迁移需要所冗余的字段,因之前只支持单集群
数据库:对应Hive库
数据表:对应Hive表
字段:对应Hive字段
主键:选择当成主键的Hive字段
是否连接额外字段:可以关联指定Hive表获取额外字段(目前跟业务绑定,只提供了固定的表)
只索引字段:指定字段只需要建索引,不需要存储,默认会存储
只存储字段:指定字段只需要存储,不需要建索引,默认会索引
MySQL接入是另外一种常见的接入方式,其填写的信息除多了MySQL连接信息外,其他的与Hive接入方式一样,平台会根据用户填入的数据库地址去读取MySQL库、表、字段供用户选取
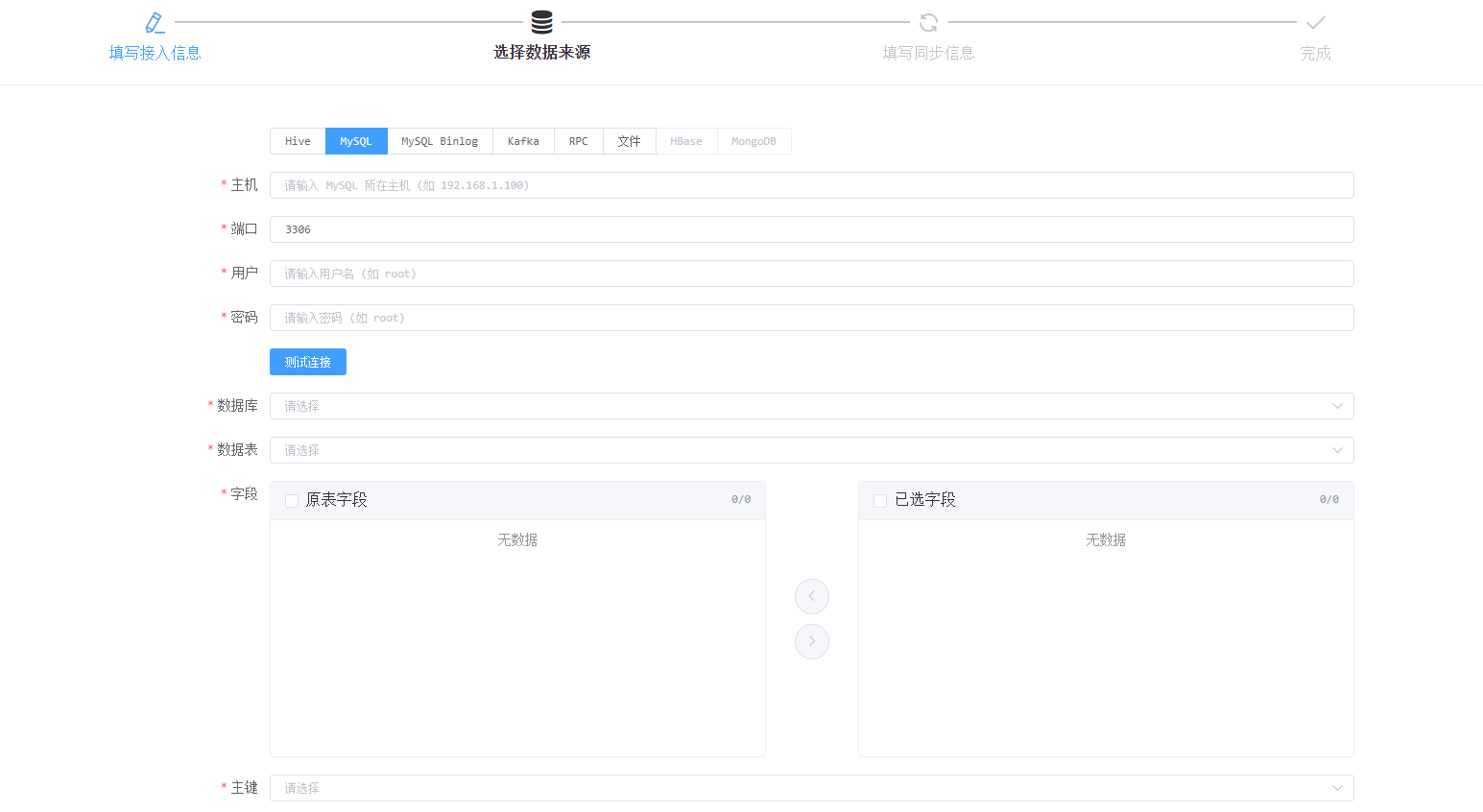
MySQL Binlog接入需要先将指定库表注册到平台的Canal处理程序上,由Canal程序统一处理Binlog发送到指定的Kafka上,后续再由Kafka消费模块进行处理
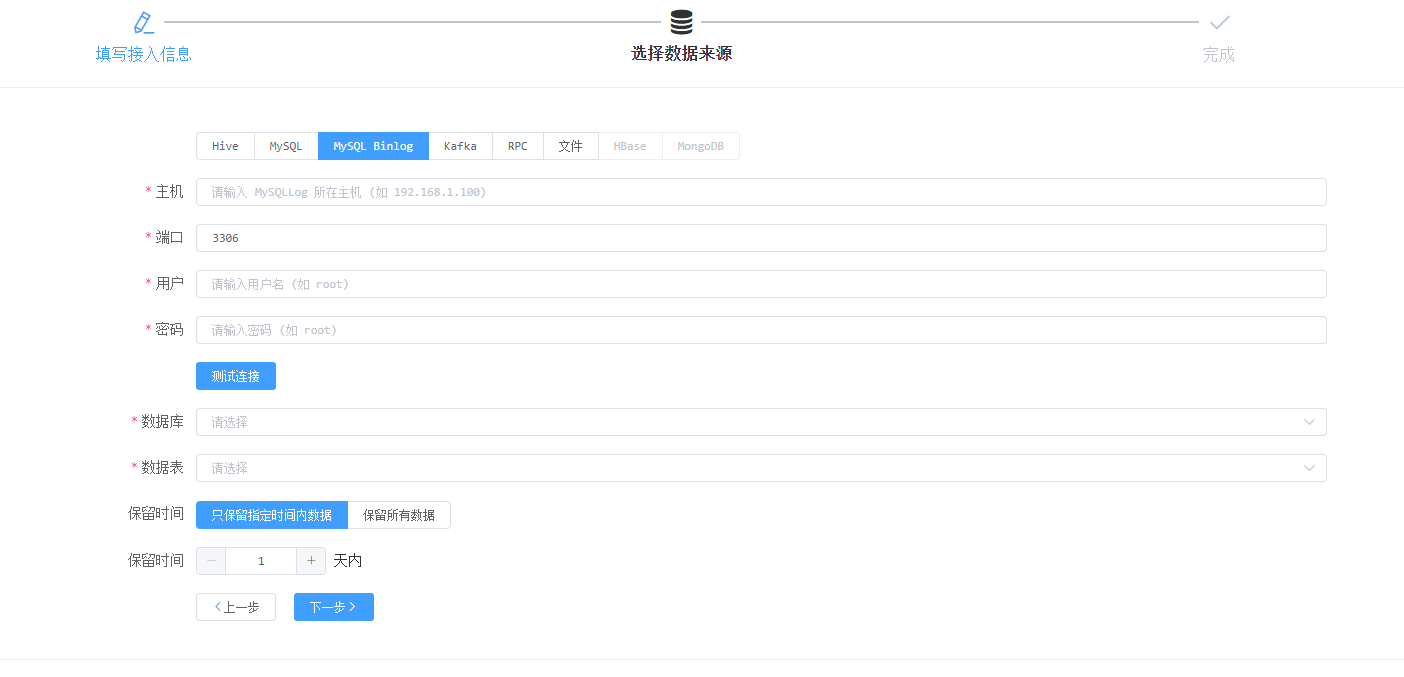
Kafka接入是由接入方定义好消息模板(定义需要写入的字段),平台根据消息模板解析出对应的字段,然后再从消费的消息中取出数据,通过Solr API写入数据(批量写入,会有一定延迟)
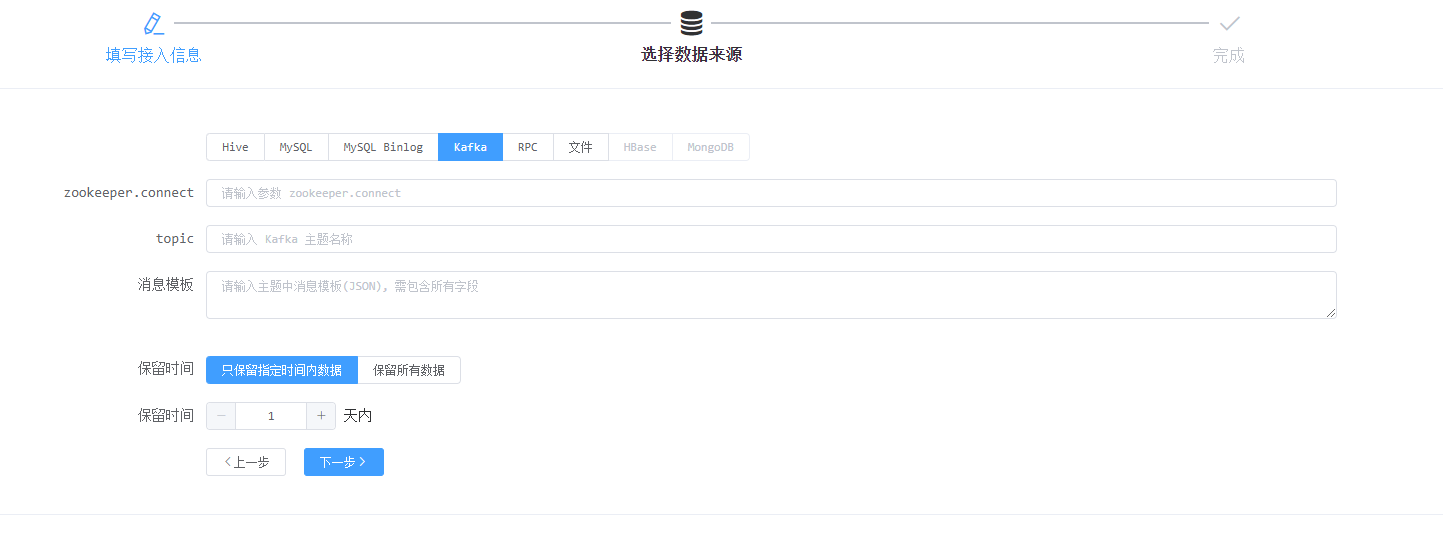
RPC接入是由接入方通过平台对外提供的RPC接口写入数据(实时写入)
文件接入按照平台字段规范组织数据,并将文件通过接口上传到指定位置,同步程序检测到文件后会进行处理
业务接入-同步信息:
同步信息跟随接入方式不同,需要填写的信息也随之不同,以下是Hive接入方式需要填写的信息:
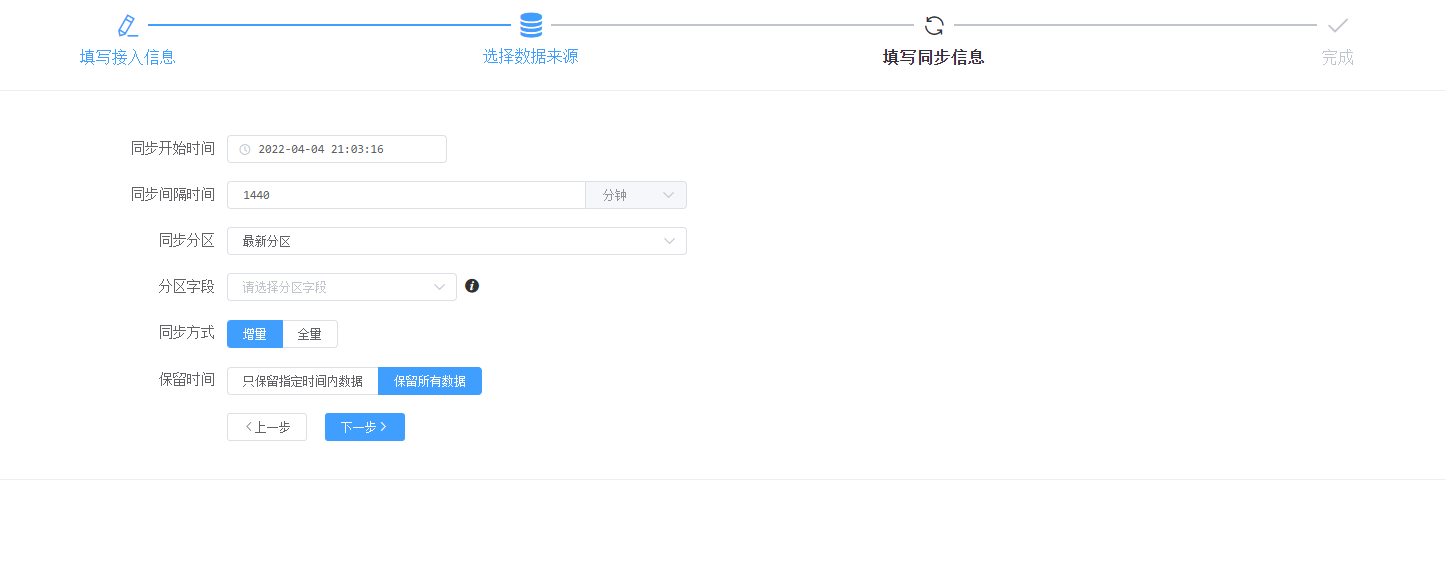
同步开始时间:指定定时同步开始时间
同步间隔时间:指定定时同步的间隔时间
同步分区:指定需要同步的分区,一般是指定最新分区,即会在同步的时候选择读取最新分区的数据
分区字段:指定作为分区的字段
同步方式:增量或全量,增量在更新时会覆盖主键相同的数据,全量在更新时会先删除数据再导入
保留时间:在增量同步方式下启用,选择数据需要保留的天数
目前保留指定天数采用的是按天生成分片,定时清理过期的分片
索引管理
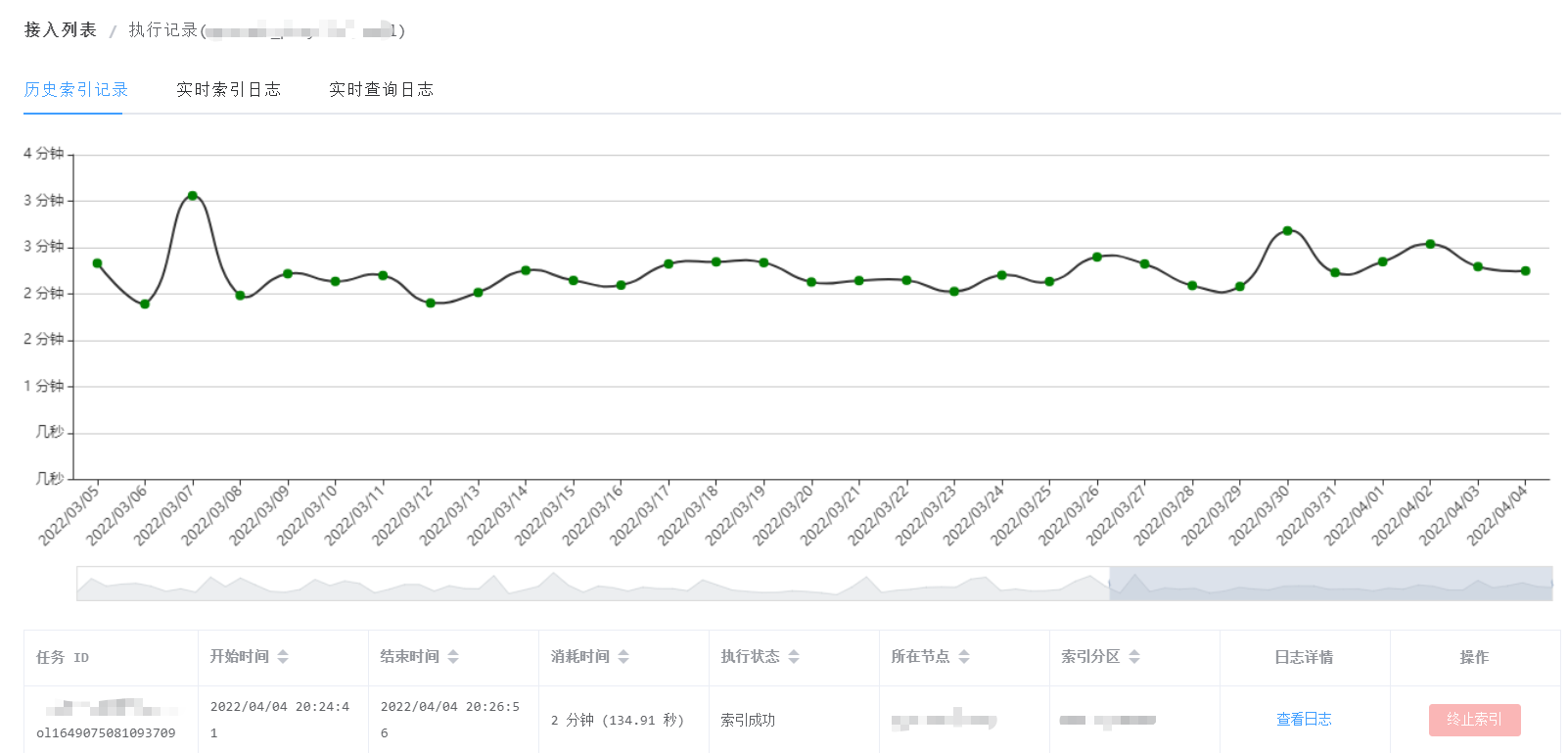
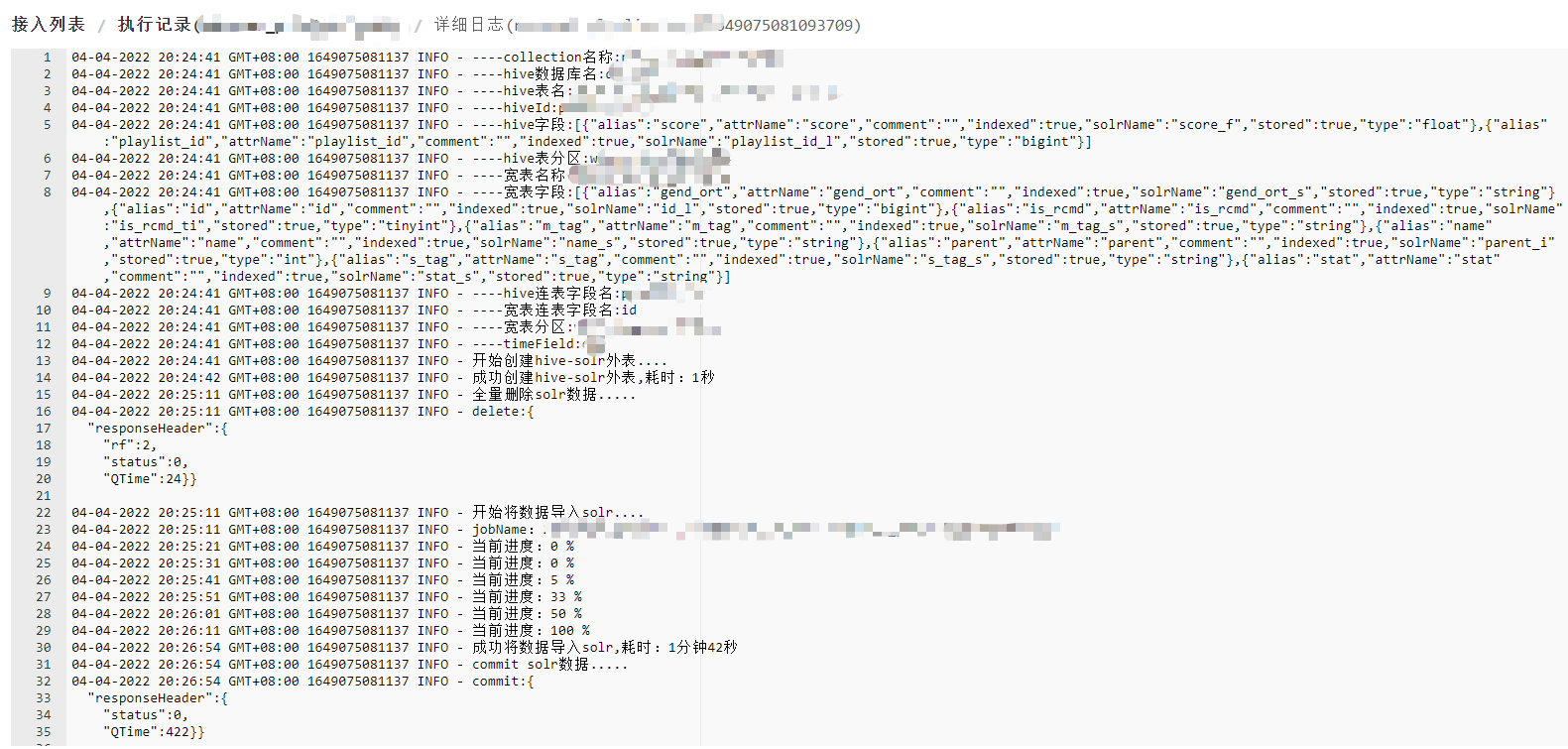
当手动或定时触发业务同步时,会生成一条索引任务,通过界面可以查看业务最新的以及历史的索引任务进行情况(耗时、执行状态等),如果想了解索引执行的详细过程也可以通过索引日志查看,平台会记录索引过程中的关键日志。如果用户不想索引任务继续执行的话,可以在界面上操作终止索引
业务数据
当索引任务执行完成,数据成功同步到平台的Solr集群后,可通过界面查看/查询具体数据,也可导出自己想要的数据
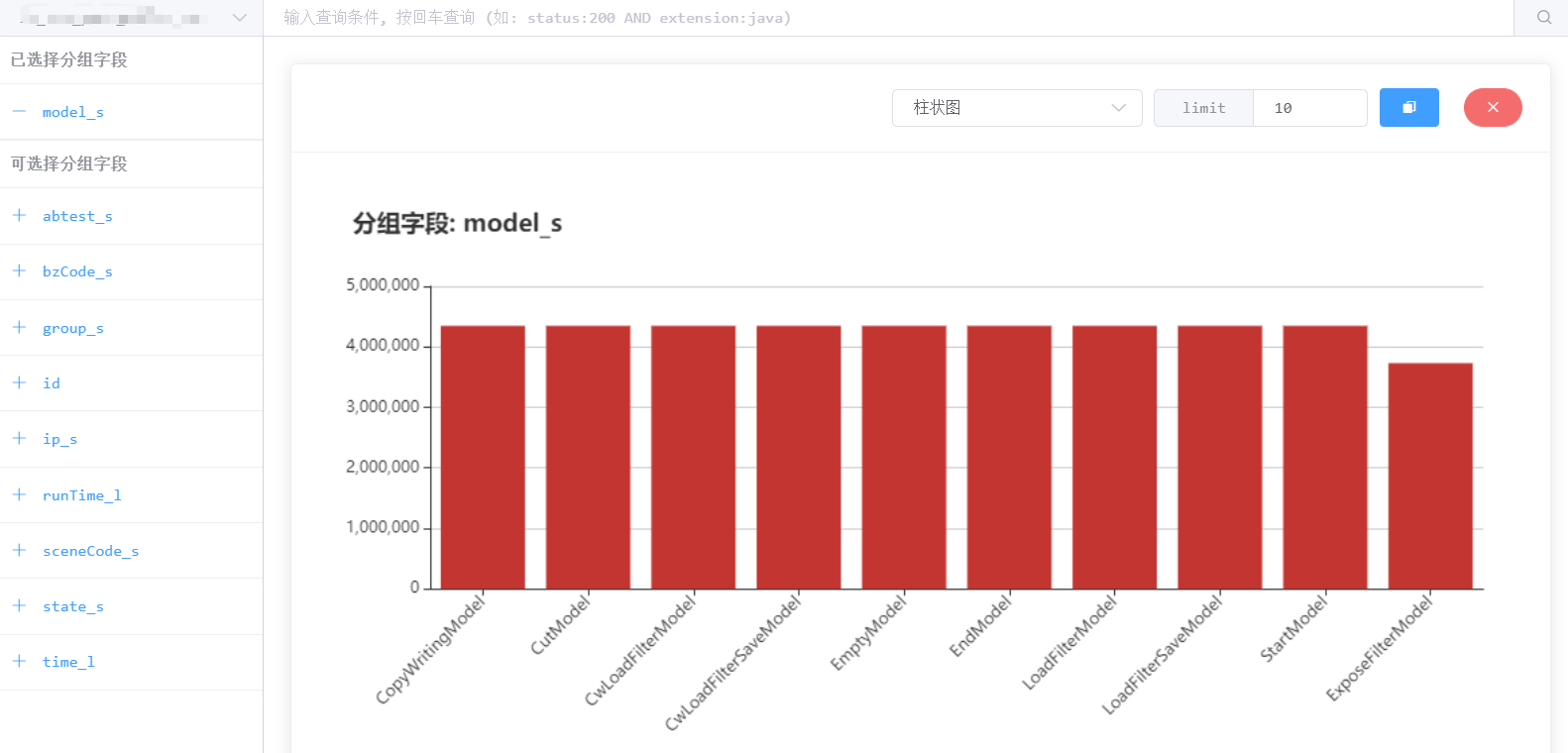
有时候用户会想要知道某个字段的数据分布,比如某个类别字段在线上分别有哪些类别,因此平台也提供了分组统计的功能,并通过图表形式展示数据的分布情况
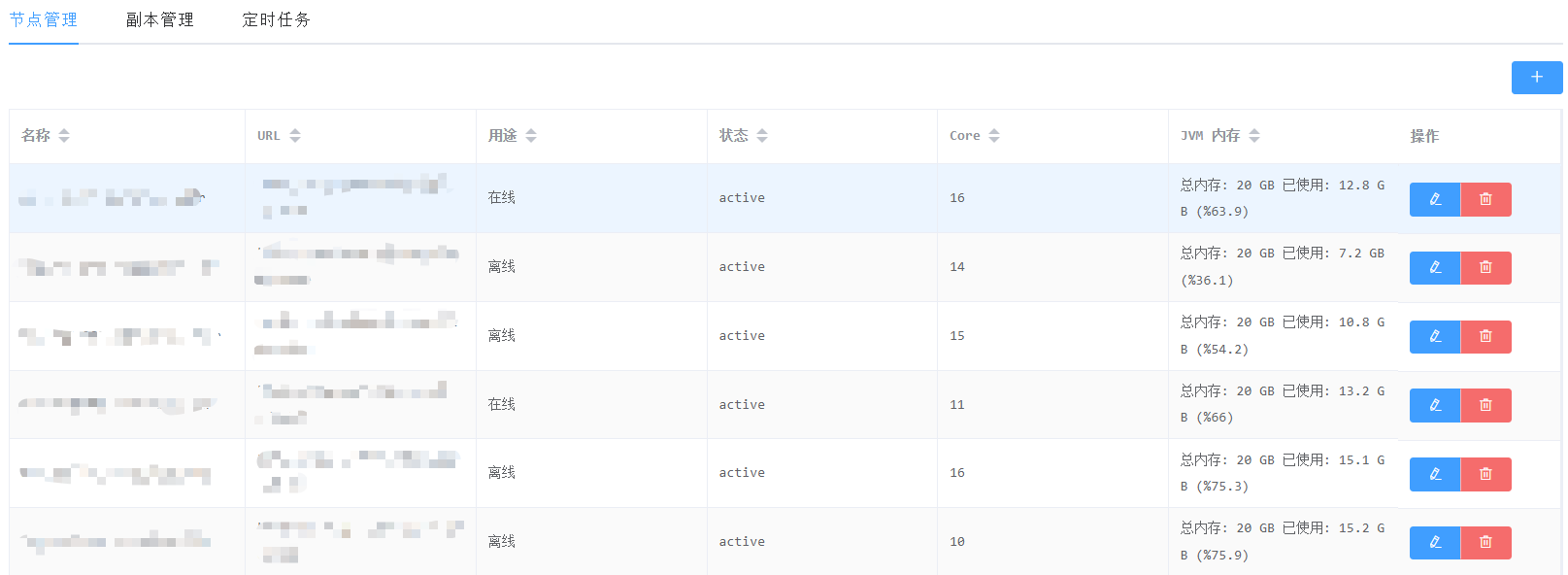
集群管理
集群管理主要包含对集群节点的注册、监控与告警,在创建Collection时会根据节点的负载情况选择合适的节点存放
展望未来
平台建设初期主要是为了支撑内部的推荐和搜索业务,随着平台核心功能逐步稳定,也开始对其他外部系统开放使用,整体反馈效果良好,但平台在某些地方还是存在设计缺陷,要推广出去乃至作为数据中台的在线检索解决方案还需持续改进,从目前来看,平台至少可以在以下的几个方面做得更好:
丰富支持的数据源类型,完善数据源扩展机制。当前Hive接入只支持平台内置的数据源,不支持动态扩展;缺乏其他常用数据源的支持,如PostgreSQL。
提供灵活的告警机制,如指定通知发送模板、触发点、发送方式等。当前告警只提供了邮件方式且只有在失败的情况下才发。
提升系统可用性。考虑索引节点宕机时如何迁移索引以保证可用等问题